Tools
This page shows various methods, techniques, algorithms, and data structures that may be useful in your system design career.
Bloom Filters¶

A bloom filter is a probabilistic data structure that tells you either:
- A particular piece of data is possibly in the set
- A particular piece of data is definitely not in the set.
It is highly memory efficient (as most filters can reside totally in memory) and easy to implement in a distributed environment. The way it works starts with an array of bit-length N. Then:
- When you add an element to the set, you take its hash then
ORthe hash's bitwise value with the bloom filter. This adds the hash's bits to the array. - To check of an element possibly exists in the set, take its hash and check if the 1's bits in the bloom filter match the 1's bits in the hash
- If the 1's match, then the element possibly already exists. If they don't, then it's a certainty the element was never added.
The reason why you can only determine "possibly exists in set" is because different hashes can mark the same bit as 1. The probability of these false positives is dependent on the size of the filter and the number of elements added to it. This can be seen in the graph below:

Consistent Hashing¶
Consistent Hashing is a load balancing technique that allows you to add and remove nodes in a pool without causing massive redistributions in the client/server mappings (called the Rehashing Problem).
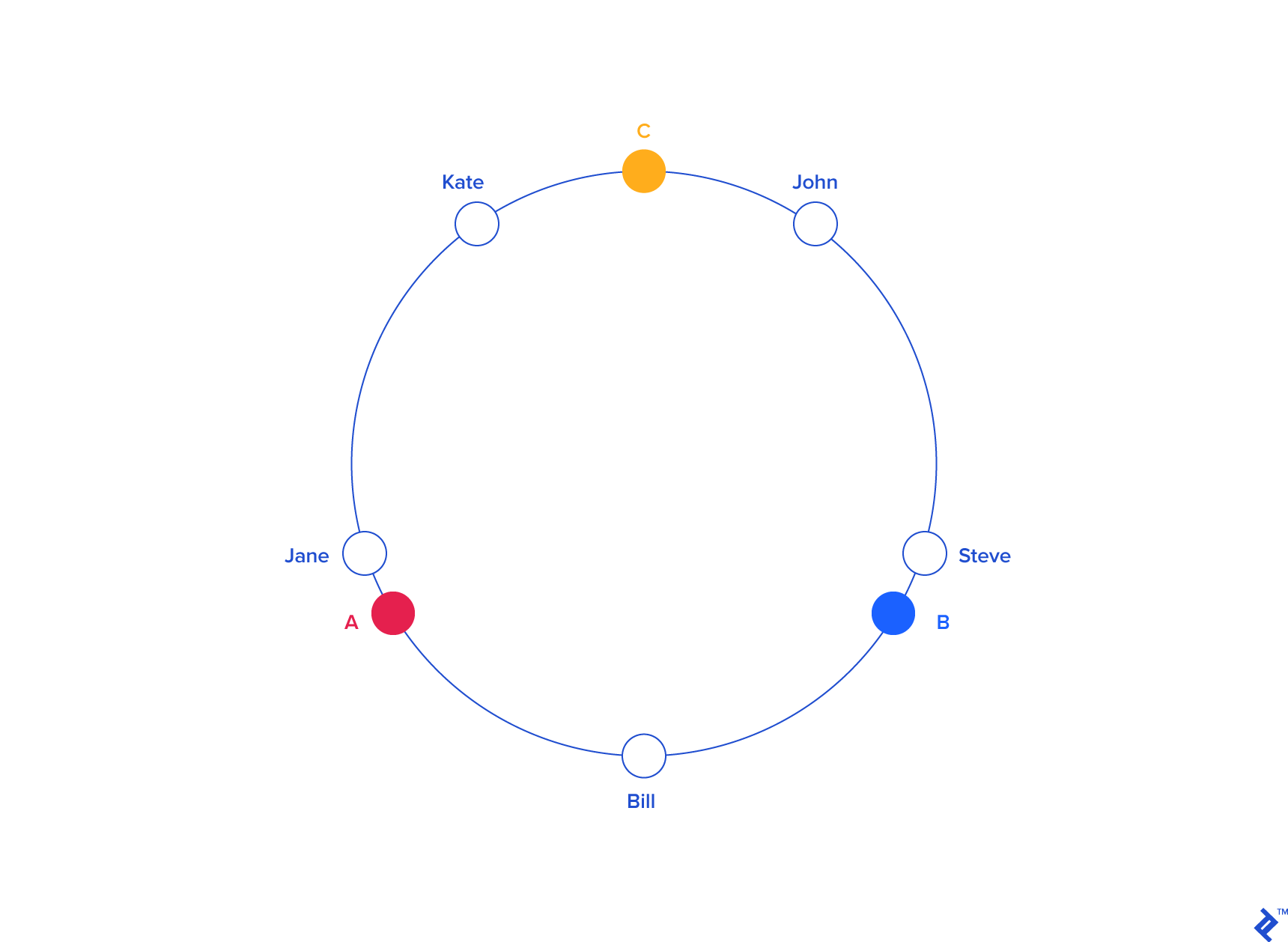
The general idea is that both servers and users live within the same hash space. The servers, more often than not, will have a hash key that depends on the name. The users will have a hash that depends on their name, but also possibly their location.
When a user is hashed, we find the closest adjacent server in a counter-clockwise manner (it could also be clockwise, it doesn't matter). When a new server gets added, there is only a small probability that any particular user needs to get re-mapped to a new server. Or in other words, the chance of a new server being blaced between a user and that user's prior server is quite low.
In the case that does happen, a re-mapping will indeed have to occur, but the overall probability is low enough that the cache misses should be minimal.
Virtual Nodes for Smoothing
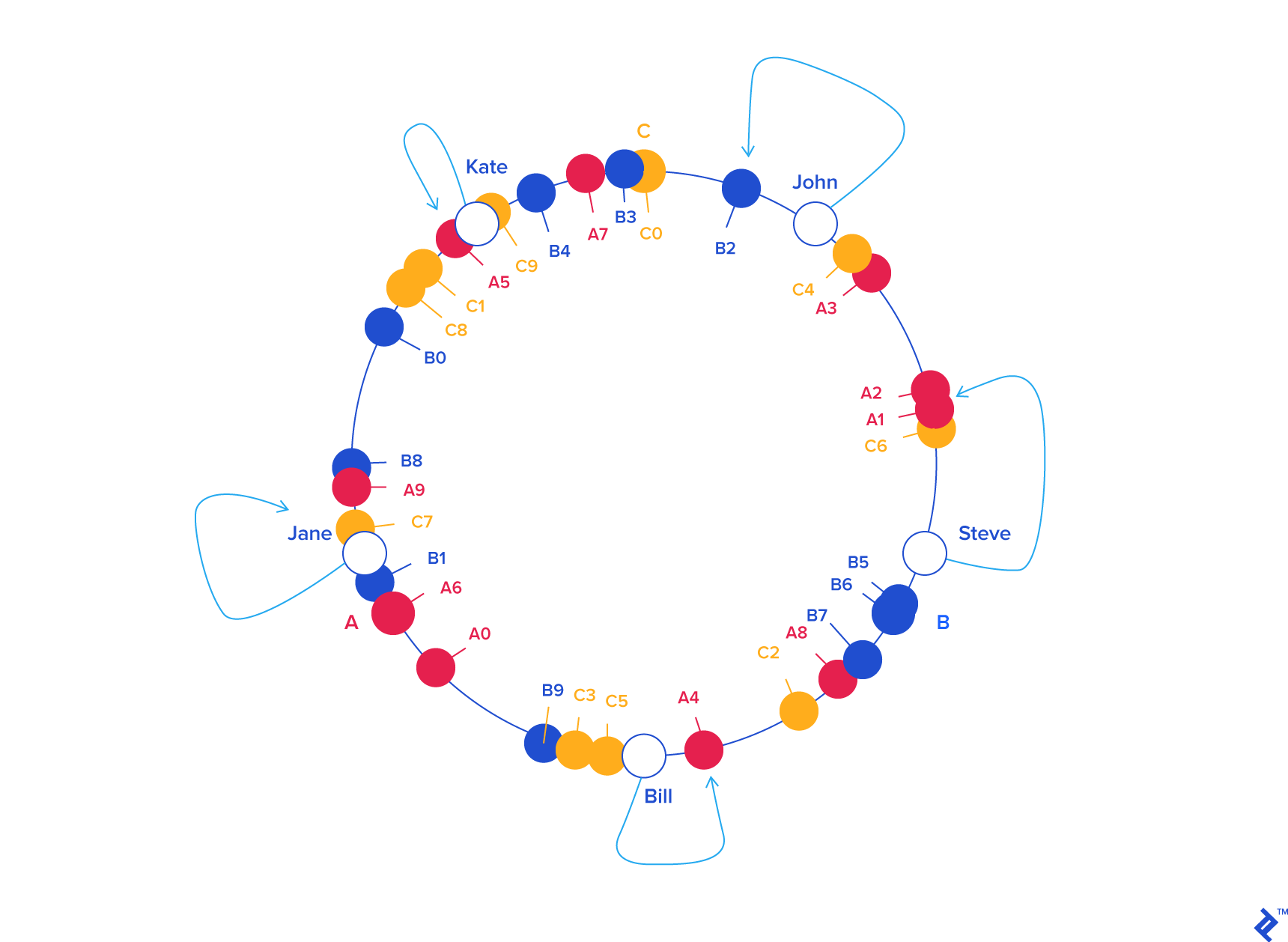 It's very likely for nodes in a hash ring to become too clumped together, which would cause uneven distribution (this is called the Hotspot Key Problem). You can smooth this out by using virtual nodes: for every real node, we also add some number of virtual nodes that maps back to the real node. This effectively causes the hash ring to become more uniformly distributed as it causes the standard deviation (in terms of empty space in the ring) to be smaller.
It's very likely for nodes in a hash ring to become too clumped together, which would cause uneven distribution (this is called the Hotspot Key Problem). You can smooth this out by using virtual nodes: for every real node, we also add some number of virtual nodes that maps back to the real node. This effectively causes the hash ring to become more uniformly distributed as it causes the standard deviation (in terms of empty space in the ring) to be smaller.
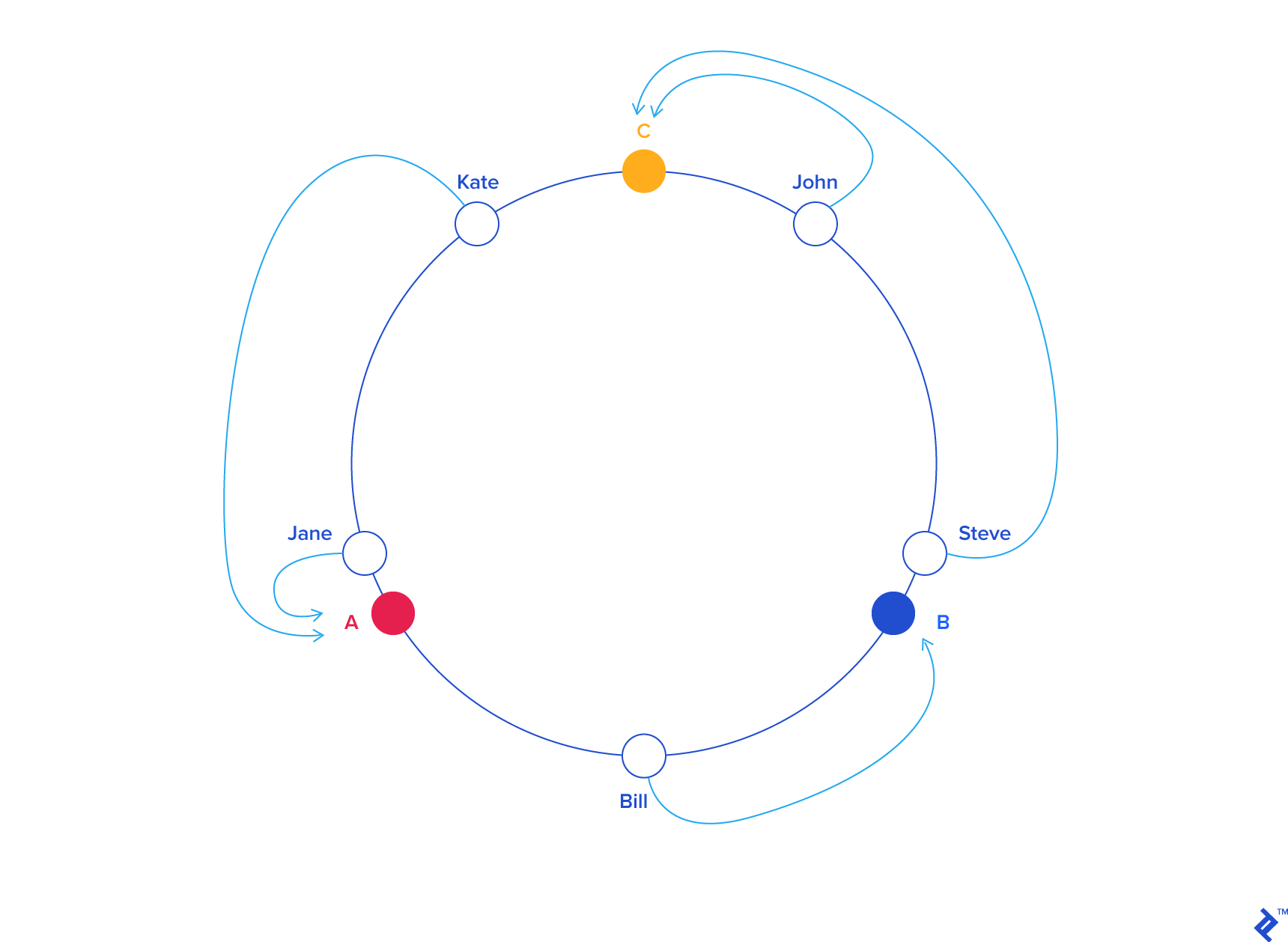
You can see in a consistent hashing scheme, adding a node to the ring will cause only some of the clients to be re-mapped.
CAP Theorem¶
CAP stands for Consistency, Availability, and Partition Tolerance. The theorem states that distributed systems can exhibit at most two of these traits, which implies that a tradeoff must be made. In most systems, partition intolerance is not acceptable as networks and systems often fail. It's a bit of an oxymoron as well to state that a system is consistent and available, but not partition tolerant. So in reality, the tradeoff is usually between consistency and availability.
Communication Protocols¶
gRPC¶

Used as a remote procedure call. Uses Protobuf to send and receive serialized structured data. Messages in protobuf are defined in a language-agnostic DSL.
Websocket¶

Websocket is a web communication protocol that allows you to asynchronously send and receive messages over the same connection. It starts its life as an HTTP connection, and then is upgraded to a websocket session. This protocol is the answer to common HTTP polling techniques that are used to periodically check for updates from the server. Some examples of where this protocol is used:
- Real-time web applications where updates need to be continuously streamed.
- Chat applications where messages arrive asynchronously.
- Gaming applications where updates are fairly continual.
Many of these kinds of data streaming problems were commonly solved through HTTP polling, however this solution is inefficient due to the constant HTTP/TCP handshakes that would need to occur even if no data was available.
Websocket is generally served through ports 80 or 443 (HTTP/HTTPS), which allows it to pass through many types of firewalls.
Polling Mechanisms¶
Short polling¶
A client would periodically poll the server for new messages. This would work but it's inefficient because it requires opening and closing many connections.
Long polling¶
Same as short polling, but we can keep the connection open until we receive new messages. The disadvantages are: - The sender and receiver might not be on the same server. - The server has no good way to tell if a client is disconnected. - It's inefficient because long polling will still make periodic connection requests even if there are no messages being sent.
Websocket¶
Websocket is a protocol that allows you to asynchronously send and receive messages over the same connection.
Service Discovery¶
When you have a pool of services, for example a pool of websocket servers that provide clients with messages in a chat system, you often need to provide the client with a list of DNS hostnames they could connect to. This process is called "Server-side Service Discovery" and there are many off-the-shelf solutions:
etcd ¶
This is a distributed key-value store that can be used for service discovery (among many other things). It uses an eventually-consistent model through the gossip-based protocol. It does not have many built-in features for service discovery as it focuses more on the key-value store.
consul ¶
consul is a Service Mesh that provides a rich suite of metrics and monitoring capabilities. It allows you to define health checks on your services. It also comes with native support for cross-datacenter replication, while etcd does not.
consul also gives you distributed key-value stores
Apache Zookeeper¶
This is another distributed key/value store that also provides service discovery.
Key-Value Stores¶
- redis
- cassandra
Redis is often chosen over etcd for key-value stores because etcd requires consensus amongst its nodes before committing changes, which slows performance. The benefit of etcd is that it provides a lot of consistency guarantees. The docs claim it follows Sequential Consistency, which means that while a write does not have to be seen instantaneously, the sequence in which writes to a piece of data are seen is identical across all processors.
Cassandra ¶
Cassandra is often compared against Redis. For a good comparison, look here. Many of the notes here are drawn from that blog.
This is used by some large chat platforms like Discord to store chat history. Some aspects of Cassandra:
- Uses wide-column store as a database model, which makes it easy to store huge datasets. It acts as a two-dimensional key/val store.
- Focuses on stability, but it's slower than other platforms like Redis. Redis becomes much slower if you store huge datasets, and thus it's more suited for highly variable datasets.
- Cassandra focuses on consistency and partition tolerance, while redis focus on availability and partition tolerance.
- Schema-free.
- Uses Java, uses thrift protocol for API.
- More useful when you have distributed, linearly scalable, write-oriented, and democratic P2P database structure.
redis ¶
Meant specifically as an in-memory key-value data store. Most commonly used for distributed key-val.
Testing Methodologies¶
Smoke Tests¶
A Smoke Test tests basic functionality of a service. It can be thought of as a rough sanity check that major features are working as expected. Smoke testing is meant ot be lightweight and quick, and can be used as a gatekeeper for more involved and expensive integration tests.
A/B Tests¶
A/B tests deploy two different implementations of a functionality and run them in parallel either in a development or production environment. The results of the two implementations are compared against each other to determine the viability of the new implementation.
Functional Tests¶
Functional tests assert that the end state of a system is as you expect. They often assert specific details, like a specific value being committed to a database. Integration tests, on the other hand, are often defined as being a specific type of functional test that is simply checking that two or more systems can successfully communicate with each other.
Integration Tests¶
Integration tests assert that two or more components of a system can properly communicate with each other. This is often used when interacting with databases: you might instantiate a Postgres database in docker-compose and assert that your application is sending valid SQL and can parse results from the database appropriately.
Durable Execution¶
According to Temporal:
Quote
Durable Execution is a development abstraction that preserves complete application state so that upon host or software failure it can seamlessly migrate execution to another machine.
Temporal.io is one such implementation of Durable Execution. The model allows your application to seamlessly continue execution even after hardware failures.